(Enlarge)
|
- INTERESTING NOTE:
- I'm sure you've noticed that when you login to the AWS console that in the top right corner is usually the name of the account holder.
- However, when you create an S3 bucket, if you have created an AWS forum account name then, instead of seeing the name of the account holder as the owner of the bucket you will see the forum account name. Fascinating, isn't it?
|

(Enlarge)
|
- Like was mentioned earlier you will need to create a bucket in your S3 partition. By default when you create the bucket only you will have access to it.
- This may also be a good time to ensure your data in the mySQL tables is of the correct data types since the data pipeline import process will perform some data type validation on your data whether you want it to or not. One such example is the correct formatting of timestamps (mentioned earlier).
|
(Enlarge)
|
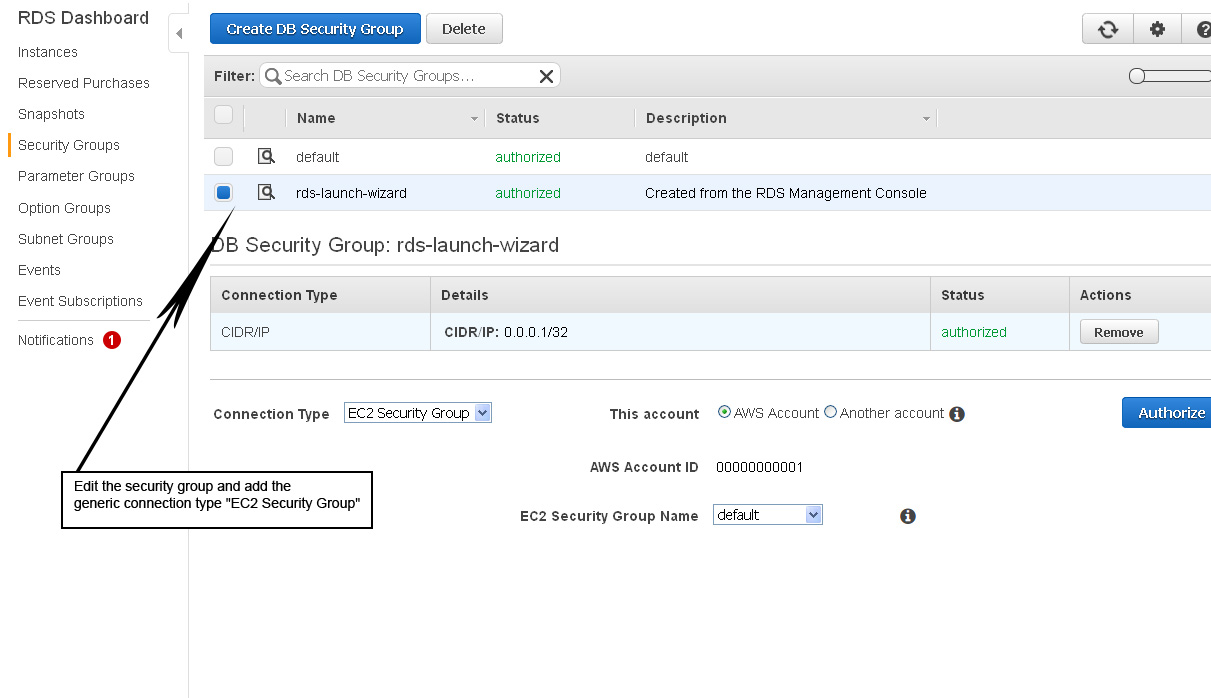
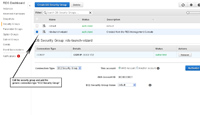
- The next thing you will need to do is to modify the RDS security group that your RDS Instance is associated to. If you used default settings when you created your RDS Instance, the security group will be "rds-launch-wizard".
- All you need to do here is add the connection type "EC2 Security Group" to it.
- Copy the RDS Instance endpoint since you will need that later for the data pipeline.
|
(Enlarge)
|
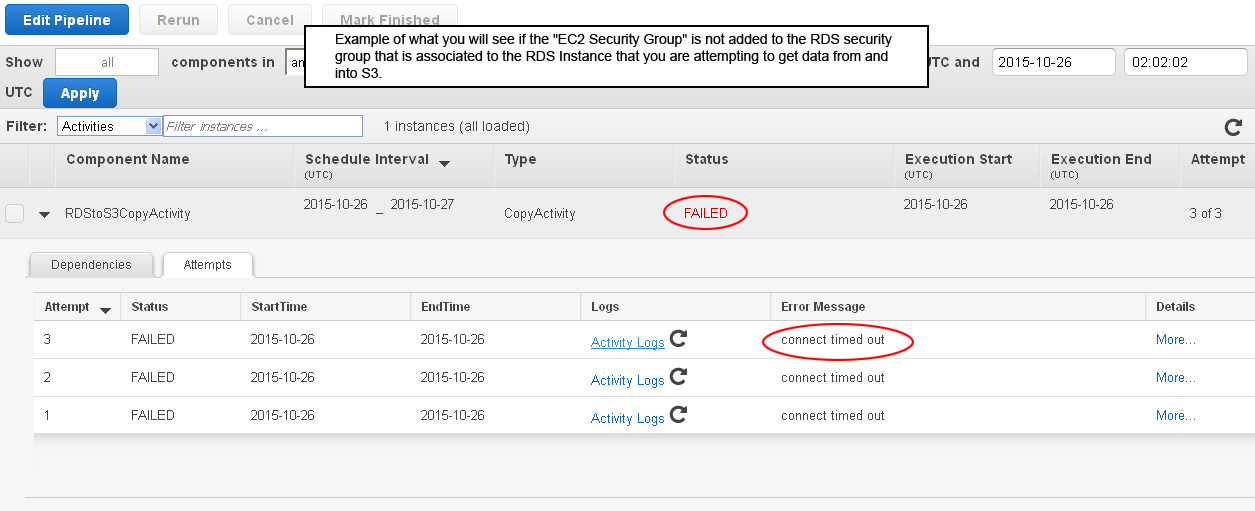
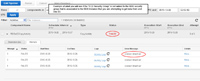
- If you fail to complete the prior step then the data pipeline will fail and the reason for failure will be "connect time out" as shown here.
|
(Enlarge)
|
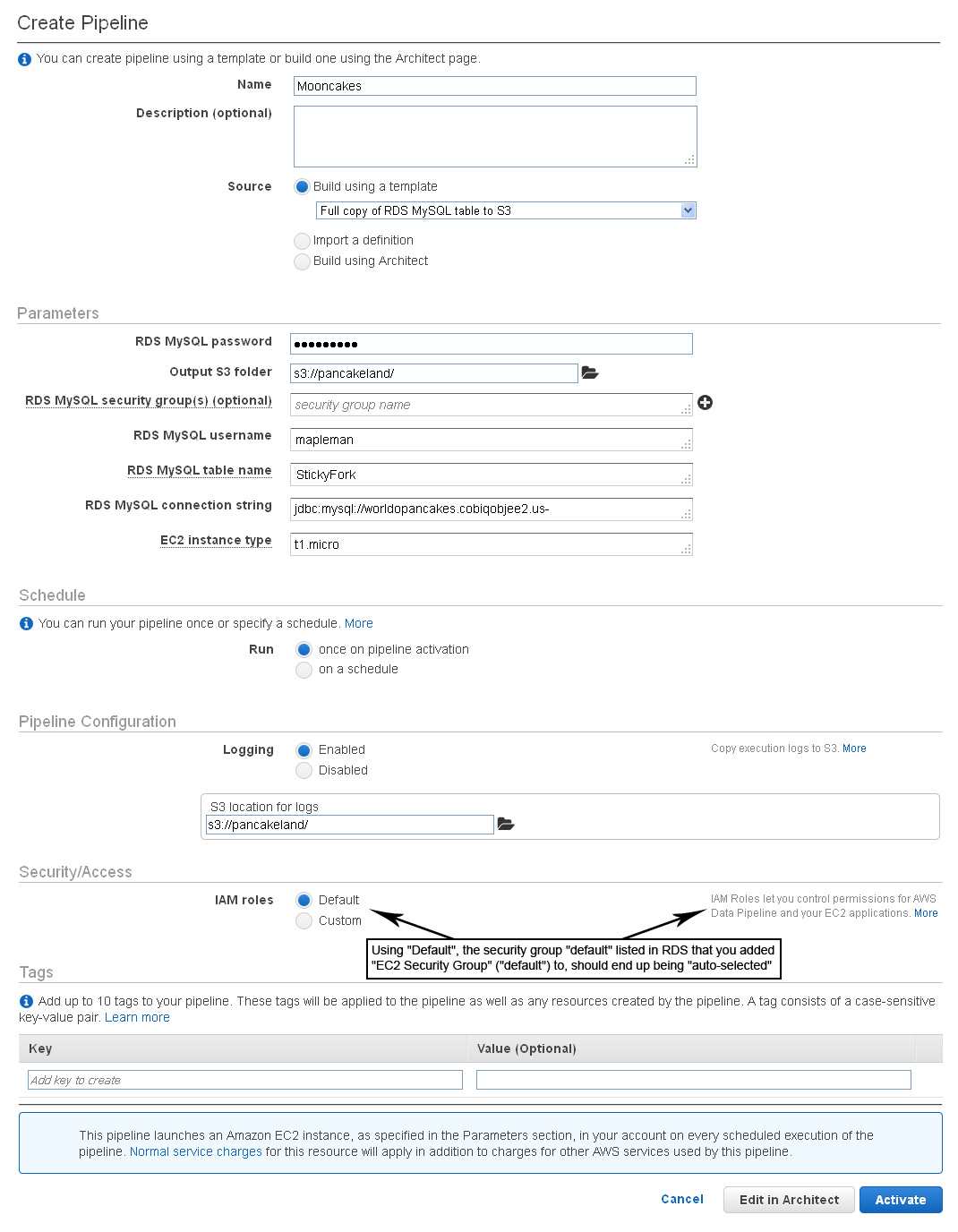
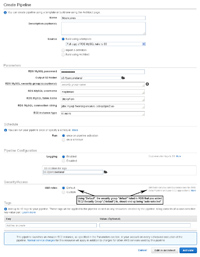
- The next thing is to go to the Data Pipeline section of AWS and create a new data pipeline (for RDS / mySQL).
- As shown here, it is pretty straight forward to complete.
- You can use the Source as "Full Copy of RDS MySQL table to S3" for putting an entire table of data into S3. This allows you to not have to re-invent the wheel by creating your own template.
- Under Schedule you can have it run on a schedule or just one time by selecting "once on pipeline activation".
- The security access IAM role should have "Default" selected.
- The time it takes for a data pipeline to run varies from a few minutes to over 10 or 15 minutes (with up to a 6GB mySQL table).
- Lastly, if you don't use any type of tagging, when using the source template provided by AWS it is important to know that the name of the folders(s) that will be created in your bucket will be TIMESTAMPS and NOT the name of a mySQL table; the actual CSV files that get created will also NOT be the name of a mySQL table. So, as you export your data table by table you may want to keep notes as to which mySQL table corresponds to a particular folder that gets created in your bucket.
|